
Ceph Storage for AI

Philip Williams
on 26 February 2024
Use open source Ceph storage to fuel your AI vision

The use of AI is a hot topic for any organisation right now. The allure of operational insights, profit, and cost reduction that could be derived from existing data makes it a technology that’s being rolled out at an incredible pace in even change-resistant organisations.
However, AI systems that deliver these insights, savings, and profits, rely heavily on access to large amounts of data. Without performant, and reliable storage systems, even the most cutting-edge AI solution will not be able to provide timely results. Additionally, these new AI related workloads cannot impact existing business applications, both need to operate together harmoniously.
In this blog, we will explore some of the requirements placed on a storage system by an AI solution, as well as the types of data used. We will introduce Ceph as one of the options available to store both AI-related data and typical business data.
The demands AI places on storage
New AI applications mean additional pressures and requirements for your storage systems. Here’s what your storage system needs in order to support new AI workloads:
High throughput
AI workloads need access to lots of data, and quickly: first, when reading raw data, and second, for writing the output following processing. It is not uncommon to see requirements in the region of 100’s GBps and over 1TBps!
Storage solutions such as Ceph allow for caching elements to be added to assist with bursty write workloads, and the ability to scale-out to increase overall system throughput.
Scalability
The AI infrastructure of today is not what the AI infrastructure of tomorrow will look like. A storage system needs to be able to adapt to the needs of AI workloads, both in its ability to scale up for capacity and throughout reasons, but also to scale down should the hardware need to be reused elsewhere in an organisation’s infrastructure.
Flexibility
Following on from scalability, a storage system needs to be flexible enough to accommodate different types of AI workloads. Not all data is created equal; some can be more important than others, and over time it’s value can change as well. For example, bank transaction data is more likely to be accessed during the first thirty to sixty days when people are checking their balances and viewing end of month statements, than say in 3 years time. However, it is still important that the data is preserved and available should it need to be accessed at that time.
Therefore your storage system needs to be capable of offering different tiers of storage to meet this requirement. A storage system such as Ceph allows a user to combine heterogeneous hardware, allowing them to mix and match over time as system needs dictate.
Reliability
The most important role that a storage system plays is storing data. There is little use of a storage system that is highly performant, but which cannot store data reliably; what good is generating and processing data if it can’t be retrieved?A solution like Ceph allows a user to choose from replication and erasure coding based protection strategies – again, to allow for a system configuration that can match business value with cost to store.
Types of AI Data
Now that we understand the characteristics that a high-quality storage system needs to provide, let’s take a look at what kinds of data are most typical in AI applications. There isn’t just “one” type of AI data. There are multiple different types, all used at various stages of developing, training and deploying AI models.
Raw and pre-processed data
This is the source data extracted and retrieved from all manner of applications and systems: chat tools, email archives, CCTV recordings, support call recordings or autonomous vehicle telemetry – just to name a few examples. This data can be in all forms: database tables, text, images, audio, or video.
Once extracted from these systems this data is typically pre-processed to ensure that it is in a useful format for training. Pre-processing can also remove otherwise redundant steps later in the pipeline, saving time and computation resources. With certain data sets pre-processing is used to anonymise the data to ensure regulatory compliance is met.
Training datasets
Training datasets are typically a subset of pre-processed data that is used to train an AI model. What makes this dataset special is that the expected model output has already been defined. It is important that these datasets are preserved so that they can be used to refine a model or evaluate its performance.
Models
The structure of an AI model – the layers and nodes – needs to be reliably stored so that the model can be redeployed in the future. Additionally an AI model contains parameters and weights that are tweaked during model training. Future adjustments can be made to these variables to fine tune the model or to deploy it in an inference role.
Results
This is the most important of all the steps of importing, pre-processing, training, and deployment. The output, or inference data, is typically the most useful and valuable data for business uses, and it must be stored so that it is available for use. In some cases, this data needs to be retained for auditing and future refinement.
Open source options for AI Storage
Finding a storage solution that delivers everything you’re looking for – cost, speed, flexibility, scalability, and support for a multitude of data sets and types – is difficult. Proprietary storage solutions can be inflexible, and public cloud services soon become costly as you grow; two areas where in-house open source solutions would be an ideal answer.
Canonical Ceph is a storage solution for all scales and all workloads, from the edge to large scale AI modelling, and for all storage protocols. Mixed workloads, with different performance, capacity, and access needs can all be accommodated by a single cluster. The scale out nature of Ceph means that hardware can be added incrementally to meet either performance or capacity needs.
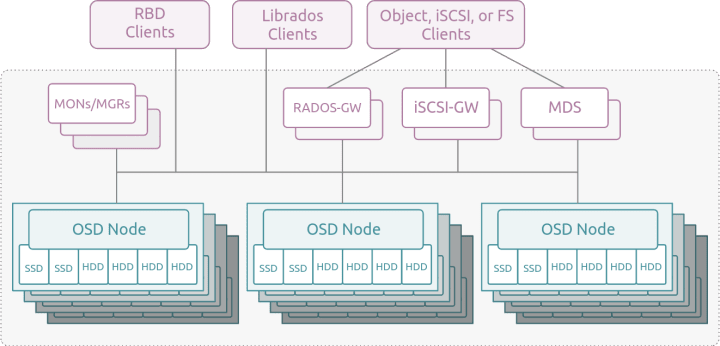
Block
Block storage needs are provided via the RADOS Block Device (RBD) protocol – a highly scalable multipath-native block transport. To support legacy environments iSCSI can also be accommodated via gateway, and in a future release highly available NVMeoF will be supported as well.
File
Shared File storage is presented either via Ceph’s native POSIX compatible protocol CephFS, or via the NFS protocol again via a gateway.
Object
An Object storage API with compatibility for both the S3 and Swift APIs is fully supported in a Ceph cluster.
Learn more

Join our webinar on using Ceph for AI workloads here and learn about:
- AI storage use cases
- Storage economics
- Performance considerations
- Typical hardware configurations
- Storage security
Additional resources
- What is Ceph?
- White paper – A guide to software-defined storage for enterprises
- White paper – Cloud storage cost optimization
- Webinar – Storage for AI
Further Reading
Learn more about Canonical’s open source infrastructure solutions.

What is Ceph?
Ceph is a software-defined storage (SDS) solution designed to address the object, block, and file storage needs of both small and large data centres.
It's an optimised and easy-to-integrate solution for companies adopting open source as the new norm for high-growth block storage, object stores and data lakes.
How to optimise your cloud storage costs
Cloud storage is amazing, it's on demand, click click ready to go, but is it the most cost effective approach for large, predictable data sets?
In our white paper learn how to understand the true costs of storing data in a public cloud, and how open source Ceph can provide a cost effective alternative!
Interested in running Ubuntu in your organisation? Talk to us today
A guide to software-defined storage for enterprises
Ceph is a software-defined storage (SDS) solution designed to address the object, block, and file storage needs of both small and large data centres.
In our whitepaper explore how Ceph can replace proprietary storage systems in the enterprise.
Interested in running Ubuntu in your organisation? Talk to us today
Performant, reliable and cost-effective cloud scaling with Ceph
Canonical Ceph simplifies the entire management lifecycle of deployment, configuration, and operation of a Ceph cluster, no matter its size or complexity. Install, monitor, and scale cloud storage with extensive interoperability.
Newsletter signup
Related posts
How to reduce data storage costs by up to 50% with Ceph
Canonical Ceph with IntelⓇ Quick Assist Technology (QAT) In our last blog post we talked about how you can use Intel® QAT with Canonical Ceph, today we’ll...
How to utilize CPU offloads to increase storage efficiency
Canonical Ceph with IntelⓇ Quick Assist Technology (QAT) When storing large amounts of data, the cost ($) to store each gigabyte (GB) is the typical measure...
Meet the Canonical Ceph team at Cephalocon 2024
Date: December 4-5th, 2024 Location: Geneva, Switzerland In just a few weeks, Cephalocon will be held at CERN in Geneva. After last year’s successful...